

By Tim Kaschinske
This is the fifth and final blog in a series focusing on how healthcare organizations are dealing with unprecedented volumes of unstructured data and how this impacts the holistic view of the patient’s data. You can read the prior blogs here:
- Much Ado About Unstructured Data
- IHE, Hard at Work Solving Healthcare’s Big Data Dilemma
- How Radiology and Oncology Deal with Multiple Forms of Patient Data
- Identifying a Patient
In my final blog, I will talk about some of the possible solutions that exist within the healthcare market today.
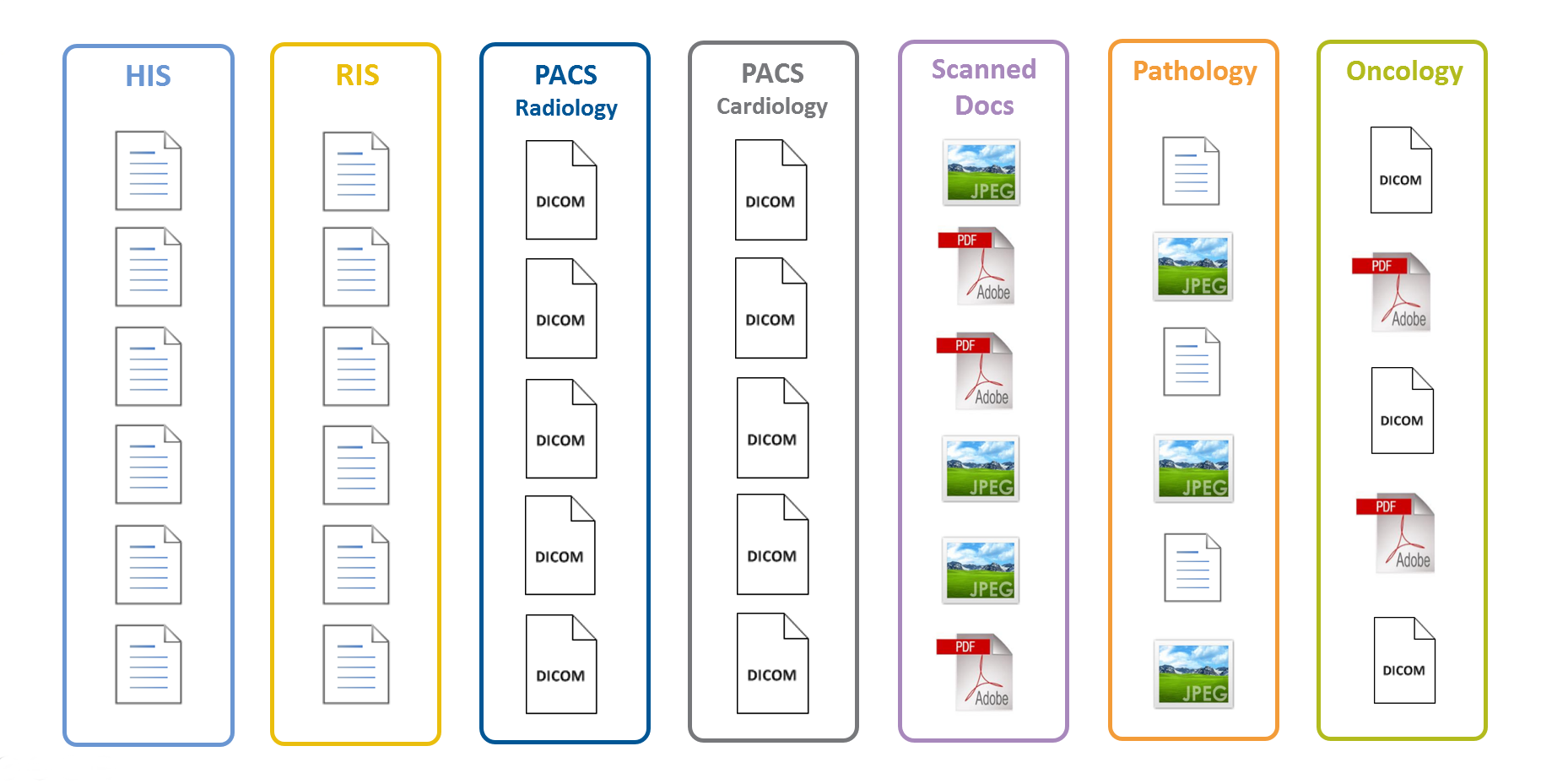
EMR
Longitudinal Patient Record
Portal
One solution that is often used in healthcare to manage disparate data volumes is that of a web portal that collects and displays patient information from various applications. There are several advantages to this approach:
- single view of the data is presented to the user,
- one interface to learn that becomes a single source of patient data for the user
- single sign on that eliminates the need to manage multiple user accounts for different applications.
The disadvantage of this is that it requires multiple integrations to different applications, and not all applications will be supported. Portals often complicate this further by segmenting the different applications within the user interface, since each application requires a different integration. This makes it difficult to search for data across applications within the portal, requiring the user to know whether data exists for a patient in an application or not.
Portals also typically provide the lowest common denominator in terms of functionality. For example, an image viewer to display DICOM images in a portal might not support all the tools available in a radiology review station. As a result portals do not support specialties well.
Portals are typically implemented as part of an EMR system in an effort to display the entire Electronic Medical Record for any given patient.
Application APIs
Another method is that promoted by IHE, which defines the use of standard API’s to exchange data between applications. The advantage to this method is that applications exchange data directly, they maintain control of their own data and one application is often defined as the “authoritative source” for certain types of data. Other applications can often query the data from the authoritative source when needed. The use of standard API’s such as DICOM and HL7 make it easier to exchange data between applications.
The disadvantage is that each application needs to implement the API, and rarely does one application support multiple API’s. As the API’s are updated over time, the applications also need to be updated to take advantage of the new updated API. Secondary access to data using an API can often negatively affect application performance.
Finally, some API’s are proprietary to specific applications. Any other application that needs to exchange data with that application needs to add support for that API. This creates an environment where not all applications can exchange data.
Independent Clinical Archive
Independent Clinical Archives are becoming popular as they use standards to acquire the data and separate the data from the application. This can have several benefits. Secondary access to the data can be routed to the Independent Clinical Archive so that it does not affect application performance. It can also enable common data management techniques for all data such as disaster recovery, support for multiple storage vendors, and even provide migration to different storage as systems reach end of life. Finally, separating the data from the application enables application retirement should that be necessary.
The disadvantage is that application data is duplicated in the repository, and it can take time to ingest the application data into the repository. In addition, not all applications support the standards necessary to interact with the repository.
The market for Independent Clinical Archives was started by the use of VNA’s for DICOM images.
Conclusion
Of the three possible solutions that we’ve talked about, the Independent Clinical Archive is the least used. Where it is used, it is often through the implementation of a VNA. Unfortunately, VNA is often associated specifically with DICOM as this is the environment where it was originally defined. All of the VNA vendors recognize this and accept that the VNA definition needs to be broadened to include non-DICOM data. Current implementations still are restricted to DICOM, however. In order to support data from all applications and across all departments, the Independent Clinical Archive cannot be limited to the use of DICOM.
In reality, all three of these possible solutions can be used together. The advantages of each solution tend to complement one another. The Independent Clinical Archive acts as a single repository of unstructured data for the portal, minimizing the integrations needed to access data. Standard API’s are used when the portal accesses data from the Independent Clinical Archive, and when the Independent Clinical Archive ingests data from applications.
Combining the strengths of these separate solutions provides a way forward to solve many of the problems that plague healthcare today.